Data compression has a simple purpose: to reduce the amount of storage space occupied by a particular set of data. Not only will this save on storage, but if the data is transmitted electronically via a network, less data needs to be sent. This could save time and money.
Take for example the images below. Each one is 8 pixels across and 8 pixels down. Each pixel for a black and white image needs just 1 bit to indicate whether it is black or white.
So each image occupies 8 x 8 x 1 = 64 bits in memory (8 bytes)

What if you could store the exact same image in less than 8 bytes? It may be possible using data compression.
One method of data compression is called Run Length Encoding. Looking at the bottom left example above, you may notice that there is a run of two whole lines of white pixels, with 3 white pixels then following on the next line. We could encode this as 8 + 8 + 3 = 19W , meaning “draw 19 white pixels”. There is then a single black pixel which we could encode as 1B. We could encode the final part of that third line as 4W or 7W if we want to include the three white pixels on the next line. This only works if we know the exact height and width of the image in pixels. We could also just do 8 pixels at a time so that every line has its own encoding. In this case the first two lines would be 8W and the third line would be 3W1B4W.
In this process we are re-encoding the initial image into another format which we hope will need less space to store. Instead of storing the state of every pixel, we use a trick to group pixels together. If the data in this re-encoded image takes up less space than the original, then we have successfully compressed the data.
For very small images, with few colours, it may not be possible always to compress the image successfully. Once images get larger and/or have colour, the savings in storage can be immense.
Activity 1
A slight variation on the method described above that works well for black and white images, is the Skip x, Draw y method. Here we decide on a background and foreground colour and size for the image, and the instructions tell us whether to skip a series of pixels (i.e. leave them in the background colour) or to draw a series of pixels (i.e. draw them in the foreground colour).
A device called a fax uses a similar method to send black and white images over a phone line so that paper documents can be scanned by a fax connected on one side of a telephone line, and printed by a fax connected on the other side. Because documents often have a lot of empty white space on them, this type of compression works well in this situation.
Use the instructions below to alternately skip and fill in pixels on each row. For example on the first row 4,11 means “skip the first 4 pixels, then fill in the next 11 consecutive pixels”
Dictionary Coding
Another method of compressing data is the dictionary method. In this case the compression relies on repeating patterns in the data to be compressed. These repeated patterns can be replaced with a code, which should take up less space than the pattern itself. The patterns and their associated codes are then stored with the data being compressed as a “dictionary” in which the codes refer to the pattern, just like words are associated with meanings in a dictionary.
For documents written in a particular human language, you can imagine that there will be many common words (e.g. and, the, as, is) that will be repeated many times in the document. The space character would also be very common since it separates pretty much every word in the document. Such documents can be compressed very successfully.
Given the dictionary below ( _ is the space character ) the word “plain” could be coded as 1001 0010 and “rain” as 0001 0010
| Item | Binary |
| the_ | 0000 |
| r | 0001 |
| ain | 0010 |
| in_ | 0011 |
| sp | 0100 |
| stays | 0101 |
| m | 0110 |
| ly_ | 0111 |
| in_ | 1000 |
| pl | 1001 |
| _ (single space) | 1010 |
Note if we had used 8 bits for each character as we would in 8 bit ASCII “plain” would occupy 5×8 = 40 bits and “rain” 4 x 8 = 32 bits whereas the compressed versions only occupy 8 bits. Of course the dictionary needs to be stored with the compressed data as well, but for a large document this should not increase the size too much given the savings that would result from the compression.
Activity 2
Use the dictionary above to compress the phrase “the rain in spain stays mainly in the plain”
Huffman coding
A very common method of compression that is actually very simple is called Huffman coding. This simply does away with the idea in ASCII that each character is fixed at 7/8 bits long and allows each letter in the alphabet to have different lengths depending on how frequently it occurs in the text to be compressed. More frequently occuring letters are given a shorter length. For example if a particular text contained lots of occurences of “a” and “s” and only one occurence of “x”, a and s could be assigned codes of “00” and “01” whereas x might be assigned “100100001”
Lossy v Lossless
Compression can be thought to fall into two different categories: lossy or lossless. In lossy compression, data is permanently lost during the compression process. With lossless compression, data that is compressed can be exactly recovered and is bit for bit identical when decompressed.
When compressing data we can decide which type of compression to use based on whether we are prepared to lose some of the data or not. Often this relies on whether the data is to be used by a human or machine. Humans are very good at working with limited or incomplete data. Our brain is constantly doing this when we hear or see. It “fills in the gaps” when data is incomplete. This is the reason why we can experience visual and auditory illusions. A famous example some years ago was an optical illusion which went viral as people argued over the colour of a dress. Some people perceived it as gold and white, others as blue and black.
Sound
MP3 compression, which massively reduces the size of music files originally taken from CDs, also makes use of “illusion”, this time with sound. In a complex recording of music or other audio some sounds are masked by others so cannot be heard. This is most obvious with white noise – which is random noise across the entire range of human hearing – which will mask most sounds unless they are sufficiently loud as you can hear in this example. The same effect happens in typical music. MP3 compression makes use of this by discarding some of the sound in a typical recording which might not be heard due to the masking effect. The brain can’t really notice the sound that has been thrown away in the compressed file. If you took a piece of music from a CD and turned it into an uncompressed WAV file, as well as a compressed MP3 file, an expert listener who really knows what to listen for, MIGHT be able to tell the difference between the original uncompressed WAV file and the compressed MP3 file when listening to them. Most average listeners would struggle to tell the difference.
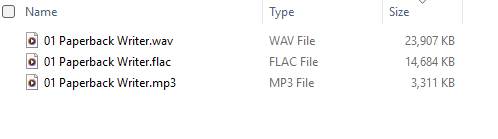
There is a huge difference in storage size. A WAV file takes up about 10 times as much space as its MP3 equivalent. We call this a 1:10 compression ratio. There are other file formats for compressed music such as FLAC or ALAC which use a lossless form of compression. These typically only achieve a 1:2 compression ratio.
Images
We can make use of the limits of human perception when dealing with colours. Look at the colours below in pairs. It’s quite difficult to tell them apart, though you should be able to see the difference between the ones on the extreme left and right.

It is so hard to tell the difference between very similar shades of colour, we could combine them into one colour and hardly notice the difference in the resulting image. This could result in space savings as instead of having a wide palette of shades of blue, we use a more restricted one. Using the dictionary coding method we mentioned previously for colours, could result in some significant space savings.

Activity 3
Take a screenshot of your desktop (hit the print screen key on your keyboard). Paste the resulting image into Microsoft Paint if you are on Windows, or an equivalent program on another OS.
- Save the file as a 24 bit bitmap
- Save it again as a JPG file
- Reload the 24 bit file from point 1 above, then save it again as a PNG file.
- Close paint. Navigate to where you saved the files. Note the differences in size and quality.
Activity 4
Which of the following could use lossy compression, and which lossless?Justify your choice for each. Video is simply a succession of moving images with an associated audio track so can be compressed in the same way as images and audio can.
| Data | Lossy/Lossless? | Justification |
| A word processed document | ||
| A website image | ||
| A wildlife photo | ||
| A studio recording | ||
| A telephone call | ||
| A Java program | ||
| A machine code program | ||
| A YouTube video |
Activity 5
Explain the difference between the following files which all contain audio recordings of the same song and all sound the same to the average listener.
Issues
The main disadvantages of compression are:
- Processing time is required to compress or decompress data
- Reduced portability of the data
Compression doesn’t come for free. Software needs to be installed or written to do the compression and decompression. It also takes time to run either process, which requires CPU processing time. The maths involved in MP3 compression for example is quite complex and the process is not quick.
If data is moved between systems, then the user receiving the data will need to be able to decompress it or have hardware/software capable of doing so. Take the example of music in a car audio system. Most can play MP3 files if they have access to a physical slot for an SD card or USB flash memory storage device. Will they also be able to play FLAC files? It depends on the car’s software whether these other compressed formats will be supported or not.
Activity 6
Answer the following questions on data compression, Q2a-c A Level Paper 1 2019 and also Q4e from the same paper.
Knowledge Check
- Why does data get compressed?
- What is run length encoding?
- What is dictionary coding?
- What types of data should not be compressed with lossy compression?
- Are there any downsides to compression?